|
 |
 Поль Н. Леру (Paul N. Leroux) Исследования показывают, что вопросы, связанные с программным обеспечением, в том числе программные ошибки и необходимость обновления, являются причиной большинства простоев систем. Автор статьи показывает, что достижение высокой готовности должно начинаться с базового программного обеспечения, на котором строятся все приложения высокой готовности, - с операционной системы. Поль Н. Леру (Paul N. Leroux) Исследования показывают, что вопросы, связанные с программным обеспечением, в том числе программные ошибки и необходимость обновления, являются причиной большинства простоев систем. Автор статьи показывает, что достижение высокой готовности должно начинаться с базового программного обеспечения, на котором строятся все приложения высокой готовности, - с операционной системы.
Системная проблема
На рынке нет недостатка в продуктах высокой готовности (High Availability, HA). Многие из них обещают надежность на уровне "пяти девяток" или даже выше. Весь вопрос в том, действительно ли высокая готовность может быть реализована на уровне всей системы целиком?
Обратимся к цифрам. Чтобы достичь надежности 99,999% приложение должно иметь непроизводительные потери времени не более чем 5,25 минуты в год, независимо от количества программных сбоев, отключений электропитания, отказов оборудования, ошибок оператора и других неожиданных неприятностей. Даже если приложение останавливается только на один час в год (например, для модернизации), это значит, что степень его готовности составляет всего "четыре девятки" - 99,99%.
Судя по этим цифрам, очевидно, что высокая готовность является системной проблемой. Таким образом, для получения системы высокой готовности все ее компоненты, включая операционную систему, аппаратную платформу и код приложений, должны разрабатываться с учетом требований высокой готовности. Например, это относится к следующим вопросам. Как операционная система обрабатывает ошибки драйвера (которые часто приводят к полному отказу системы)? Может ли ОС немедленно перезапустить драйвер без сброса системы? Или в этом случае вся система должна быть перезагружена?
Для высокой готовности имеет значение даже физическая защита. Если система расположена там, где неуполномоченный персонал может умышленно или неумышленно физически повредить ее, то такую систему практически уже нельзя отнести к системе высокой готовности. Обеспечение высокой готовности также включает в себя вопросы обучения операторов, а также учета т.н. человеческого фактора. Если сбой системы требует ручного вмешательства (например, замены вышедшей из строя платы центрального процессора), то оператор должен знать, как быстро решить эту проблему, а сама система должна быть разработана с учетом необходимости быстрого проведения ремонтных работ.
Даже если утверждается, что некоторое решение может обеспечить для вашей системы высокую готовность, это может быть вовсе и не та готовность, которая требуется для пользователя. Речь идет о том, что настоящая высокая готовность, по сути, не ограничивается только предотвращением сбоев. Система высокой готовности должна быть способна восстанавливаться после любой ошибки или модернизации за очень короткий (и, по возможности, предсказуемый) период времени. Это можно выразить простой формулой (см. формула 1), в которой А означает готовность (availability), MTTF (mean time to failure) - среднюю наработку на отказ; MTTR (mean time to repair) - среднюю наработку до ремонта (среднее время, необходимое для возвращения системы к работе после выхода из строя или модернизации одного из компонентов):
A = MTTF ÷ (MTTR + MTTF)
Формула 1
Из приведенной формулы видно, что система А могла бы чаще выходить из строя, чем система В, даже если бы обе системы имели одинаковый уровень готовности, при условии что у системы А показатель MTTR ниже, чем у системы В. Но станет ли от этого система А менее удобной или более опасной для пользователя? Конечно, все зависит от приложения. Очевидно, для достижения значительного уровня высокой готовности системный разработчик должен прежде всего понять, какой вид сервиса (и, вместе с тем, какие простои в работе этого сервиса) предпочли бы пользователи, и затем разрабатывать систему в соответствии с этими требованиями.
Показатель высокой готовности также не имеет смысла без учета того, как обрабатываются частичные остановки в предоставлении сервиса. Например, допустим, производительность сети ухудшается до того предела, при котором качество передачи данных становится неприемлемым. В этом случае система может оставаться в рабочем состоянии, но действительно ли она доступна для пользователя? Конечно, не вполне. Фактически, эта ситуация ставит еще один вопрос: управление сетью (в том числе технологии с применением избыточных сетевых соединений или выравнивания нагрузки) может составлять еще одну часть в общем уравнении высокой готовности.
Программное обеспечение: самая большая проблема
Если бы дело было только в аппаратном обеспечении, то большинство системных разработчиков могли бы достичь высокой готовности, придерживаясь всего нескольких проверенных временем принципов:
- отдавать предпочтение схемотехнике, а не механике;
- избегать использование вентиляторов - вместо них применять устройства с минимальным тепловыделением;
- применять детали, разработанные с учетом возможности легкой замены или ремонта;
- подбирать прочную конструкцию.
В действительности на рынке существует большое разнообразие аппаратных платформ "высокой готовности", в которых реализованы эти принципы. Многие из них основаны на стандарте CompactPCI или AdvancedTCA, которые поддерживают ряд возможностей высокой готовности - например, "горячую" замену оборудования (hardware hot swap) для динамической замены устаревших или вышедших из строя компонентов.
Однако самой большой проблемой является программное обеспечение. Исследования показывают, что вопросы, связанные с программным обеспечением, включая программные ошибки и необходимость обновления, являются причиной большинства простоев в предоставлении сервиса. Поэтому достижение высокой готовности должно начинаться с базового программного обеспечения, на котором строятся все приложения высокой готовности, - с операционной системы.
Драйвер, сам себя "исцеляющий"
Для того чтобы оценить роль операционной системы, рассмотрим принцип локализации неисправностей и восстановления - ключевое понятие в системе высокой готовности. В соответствии с этим принципом, неисправность в каком-либо программном или аппаратном компоненте не должна приводить к ошибкам в других компонентах; в противном случае это может вызвать сбой всей системы. Более того, неисправный компонент должен быть быстро заменен или перезапущен, не прерывая работы остальных частей системы.
Это требование ставит неустранимую проблему для обычных операционных систем реального времени (ОСРВ), поскольку в них большинство или даже все программные компоненты выполняются в том же адресном пространстве памяти, в котором работает ядро операционной системы. При такой архитектуре ошибочный указатель даже незначительного компонента может стереть содержание адресных ячеек ядра и таким образом привести к аварийному отказу всей системы - какая уж тут "локализация неисправностей"!
В некоторых ОСРВ эта проблема решается путем запуска приложений в отдельных адресных пространствах с защитой памяти. Если приложение пытается обратиться к другому адресному пространству, блок управления памятью (MMU) перехватывает ошибку и извещает о ней операционную систему, которая затем может выполнить соответствующее действие (например, "убить" вызвавший ошибку процесс и перезапустить его). К сожалению, такие ОС "привязывают" драйвера, стеки протоколов, файловые системы и другие системные службы к ядру, а это означает, что любой из этих компонентов может вызвать сбой ядра. Другими словами, каждый драйвер или стек протоколов становится т.н. единой точкой сбоя (Single Point of Failure, SPOF), т.е. компонентом, сбой которого может привести в нерабочее состояние всю систему.
С этой точки зрения, архитектура на основе микроядра, используемая в операционной системе реального времени QNX Neutrino, можно сказать, идет на шаг вперед, так как в такой архитектуре каждая системная служба работает в отдельном адресном пространстве с MMU-защитой. Драйверы и наборы протоколов, в которых возник сбой, больше не действуют как единая точка сбоя. Их можно остановить (и автоматически перезапустить) до того, как они вызовут сбой других служб (см. рис. 1).
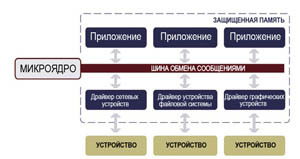
Рис. 1
Исправление ошибок до их возникновения
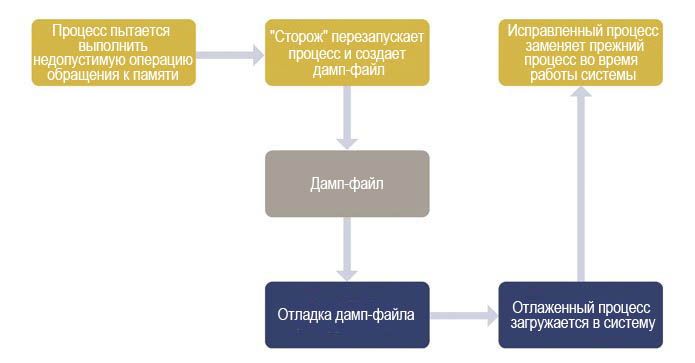
Этот последний тип архитектуры ОС позволяет выполнить еще одно ключевое требование высокой готовности: возможность исправлять программные ошибки до того, как они возникнут. Например, если драйвер пытается выполнить операцию записи в область памяти, выделенную для другого процесса, то блок управления памятью уведомит об этом операционную систему, которая затем может передать управление программе, называемой программным "сторожем" (или "монитором процессов"). В этом случае "сторож" может выполнить два действия:
- перезапустить драйвер и, при необходимости, его зависимые процессы;
- генерировать дамп-файл процесса, который можно проанализировать отладочными инструментами.
При помощи дамп-файла разработчик может сразу же идентифицировать строку кода, которая вызвала сбой, и изучить диагностическую информацию (например, содержание элементов данных и историю вызовов функций). Благодаря этой информации, разработчик может быстро разработать исправление, которое можно загрузить в другие системы для предотвращения аналогичных неполадок (см. рис. 2).
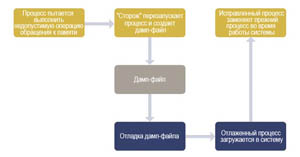
Рис. 2
Более того, программный "сторож" можно использовать для отслеживания системных событий, которые "невидимы" для обычных аппаратных "сторожей". Например, аппаратный "сторож" может обеспечить правильную работу драйвера в отношении оборудования, но с трудом сможет отследить корректность взаимодействия программ с этим драйвером. Эту задачу может решить программный "сторож". При необходимости он может выполнить нужные действия до того, как с драйвером возникнут какие-либо проблемы.
Программный "сторож" может выполнять и некоторые другие функции, например:
- Отправка квитанций работоспособности позволяет "сторожу" проводить мониторинг работы любого программного компонента и обнаруживать проблему до того, как она станет неисправимой.
- Повышение устойчивости к внутренним сбоям - если "сторож" аварийно останавливается по какой-либо причине, он должен немедленно восстановиться к своему предыдущему состоянию.
- Программный интерфейс "сторожа" предназначен для того, чтобы сообщить "сторожу", какие действия он должен выполнить при возникновении состояния ошибки.
Модернизация
Необходимость модернизации ПО высокопроизводительного сетевого элемента или промышленной системы управления может возникать несколько раз в году. Для большинства таких систем простой недопустим - система должна предоставлять сервис даже во время модернизации. Как и в других вопросах, связанных с программным обеспечением систем высокой готовности, возможность модернизации ПО определяется непосредственно операционной системой.
В большинстве современных ОС модернизация кода приложений не представляет проблем. В некоторых ОС возможно даже динамическое присоединение к ядру новых системных служб, например, драйверов и стеков протоколов. Однако эти службы работают в пространстве ядра, поэтому их нелегко остановить, удалить или заменить на новые версии. Модернизация этих компонентов становится непростой задачей, а иногда даже невозможной, без полной остановки и перезагрузки системы.
Чтобы справиться с этими проблемами, ОС должна, как минимум, давать возможность динамической выгрузки драйверов и других служб. Однако во многих случаях может возникнуть необходимость модернизации драйвера, не прерывая сервиса, который обеспечивает этот драйвер. Поэтому ОС должна давать возможность запуска новой версии драйвера во время работы старой версии, а затем обеспечивать аккуратное переключение с предыдущей версии драйвера на новую. После полного завершения переключения ОС должна остановить старый драйвер и освободить все используемые им ресурсы.
Разработка
Разработка систем высокой готовности требует некоторого "раздвоения личности". С одной стороны, системный разработчик должен добиться того, чтобы сбои в программном и аппаратном обеспечении случались как можно реже. С другой стороны, разработчик должен понимать, что сбои будут происходить, и поэтому должен предусмотреть меры для гарантированного быстрого восстановления системы.
Вопрос в том, какие меры необходимы? Чтобы ответить на этот вопрос, разработчик должен сначала определить, какие службы в системе действительно требуют высокой готовности и какой уровень высокой готовности нужен для каждой из них. После этого разработчик может начать определение потенциальных единых точек сбоя (SPOF), т.е. всех компонентов, отказ которых может затруднить или остановить предоставление сервиса (например, центральный процессор, сетевая карта, блок электропитания, программный модуль и т.д.).
Резервирование
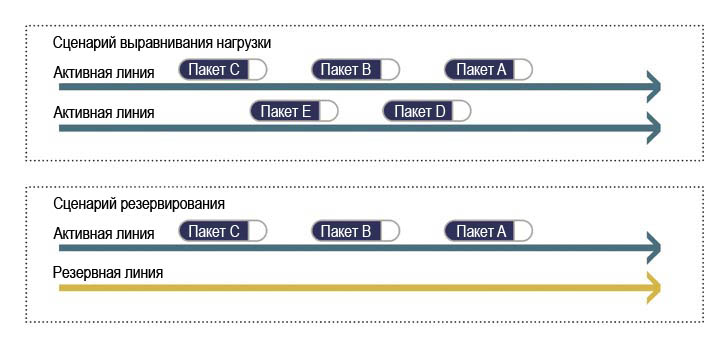
Определив потенциальные единые точки сбоя, разработчик принимает решение о том, какой вид резервирования применять. Существует два основных варианта выбора: резервирование N (2N, 3N...), где каждый компонент дублируется, и резервирование N+1, где резервируются только отдельные компоненты. Конструкция 2N может обеспечить более быстрое время переключения по сравнению с вариантом N+1, но также может значительно увеличивать стоимость (например, в случае коммутаторов, в которых большое количество соединений ввода/вывода). Во втором случае одно запасное соединение может служить в качестве резервного для нескольких активных соединений.
Резервирование можно применить к любому ресурсу, включая, например, сетевые линии связи. Резервные линии связи могут действовать как запасные или обеспечивать выравнивание нагрузки для получения большей пропускной способности (см. рис. 3).
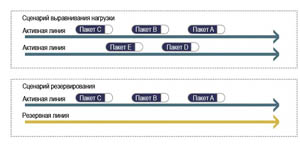
Рис. 3
Системный разработчик должен выбрать не только форму резервирования, но и модель перезапуска резервных компонентов. Например, при конфигурации 2N резервная система может работать как горячий резерв (полностью инициализированный), теплый резерв (частично инициализированный) или холодный резерв (неинициализированный). Горячий резерв может обеспечить самое быстрое восстановление, но он сложнее в разработке, поскольку резервный узел должен всегда иметь полную и свежую информацию о состоянии системы.
В действительности, вопросы системной разработки касаются не только резервных компонентов, но и любых приложений, взаимодействующих с этими компонентами. Например, допустим, узел предоставляет вычислительные ресурсы для клиентских приложений по сети. Что происходит, если этот вычислительный узел выходит из строя, и приводится в действие другой узел, работающий как горячий резерв? В этом случае все клиентские приложения должны переключиться на этот другой узел (т. е. резервную систему).
В большинстве ОС реализация такого аварийного переключения (failover) может быть довольно сложной и потребовать дополнительного кода, связанного с сетевым взаимодействием. Но если ОС обеспечивает прозрачный механизм межзадачного взаимодействия, в котором приложениям вообще не требуется знать, к какому узлу они обращаются, тогда сложности с переключением на резервный узел практически исчезают. Например, в распределенной операционной системе QNX Neutrino доступ к таким ресурсам, как диски, файловые системы и порты ввода/вывода на других узлах, является настолько прозрачным, что приложению даже не нужен специальный код, чтобы узнать, на каком узле расположен тот или иной ресурс. Таким образом, с точки зрения приложения, между обращением к главному или резервному компьютеру фактически нет никакой разницы (см. рис. 4).

Рис. 4
Системный разработчик может также исключить единые точки сбоя путем распределения приложений и служб по кластеру слабосвязанных центральных процессоров, которые могут размещаться как на одном шасси, так и на физически разных машинах. В случае применения кластера большинство служб может продолжить работу даже при выходе из строя одного из узлов. В общем, это все равно, что складывать яйца не в одну, а в несколько разных корзин. Кроме того, кластеризация может обеспечить более высокую производительность, поскольку каждый узел добавляет в систему свои вычислительные мощности, память, пропускную способность средств ввода/вывода и т.д.
Тем не менее, сложным является вопрос о том, какие именно приложения и аппаратные ресурсы должны быть распределены на каждый узел. По сути, до стадии интеграции трудно определить, насколько оптимально распределены процессы или периферийное оборудование в кластере. Однако задача упрощается, если ОС обеспечивает прозрачное межзадачное взаимодействие. Например, при таком механизме приложения могут в любой момент обращаться к дисководу, даже если этот дисковод был перемещен на другой узел, - изменения в исходном коде приложения не потребуются.
Итак, высокая готовность требует системного подхода, который учитывает все: от тщательно проверенных паянных соединений до хорошо обученных системных администраторов. Тем не менее, для большинства приложений критического назначения стоимость реализации системы высокой готовности обычно намного меньше стоимости их вынужденного простоя. Это особенно актуально сегодня, когда все больше производителей ОС, аппаратных платформ и систем предлагают продукты с поддержкой высокой готовности, что избавляет системного разработчика от необходимости делать все с нуля. Конечно, изначально не может быть высокой готовности, разработанной сразу для всех возможных систем, однако существует много уже готовых инструментов, предназначенных для их создания.
Поль Леру (Paul Leroux) является техническим аналитиком компании QNX Software Systems, в которой он работает на разных должностях с 1990 года. К сфере его деятельности относятся вопросы, связанные с архитектурой ОС, системами высокой готовности и интегрированными средами разработки.
|
|